Introduction
In the previous installment I provided the emlxsoverhead.d script for measuring overhead on the Emulex HBA and explained its internal functioning. In this installment I’ll explain how I used this script to diagnose and analyze a real-world production problem with high I/O latency. The problem appeared on a Solaris server which is used to run a consolidated Oracle database platform, but the findings can be applied to any low latency application running on a Solaris server equipped with Emulex HBAs.
Defining the Problem
Oracle database log writer process was reporting I/O outliers longer than 500 ms several thousands times per day:
Warning: log write elapsed time 836ms, size 2KBAlthough the throughput was very good and “only” 0.001% of the total I/O operations were running longer than 500 ms, in the case of the log writer of a OLTP database this is a critical problem, because commit doesn’t return until the block gets written in the file system.
Firstly, I confirmed with the script zfsslower.d that the outliers are also seen on the file system level. Secondly, I did the same for the block devices with the script scsi.d . After confirming high latencies on the block devices I checked with a storage administrator whether he was seeing latencies on the SAN components, but there weren’t any. At this point, I had to develop the script emlxsoverhead.d as I couldn’t find anything else to measure the latency on the I/O stack layer lower than the block devices.
I was able to pinpoint the problem after evaluating the output of emlxsoverhead.d :
TIMESTAMP TOTAL(us) EMLXS(us) I/O START(us) I/O INTR(us) QUEUE(us) I/O DONE(us)
[...truncated...]
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
2016 Apr 7 12:13:04 1238999 1238914 3 6 1238738 165
[...truncated...]The column TOTAL shows latencies of more than 1.2 seconds which are almost entirely due to waiting on the completion queue (column QUEUE). It is a paradox that the whole round trip to SAN lasted only 85 us (microseconds! , TOTAL – EMLXCS) and then the packet waited for more than 1.2 seconds on the completion queue! I suspected some serious deficiency in the device driver code and decided to pursue this further.
Drilling Down
Let’s recall the model of processing in the driver I built in the previous installment :
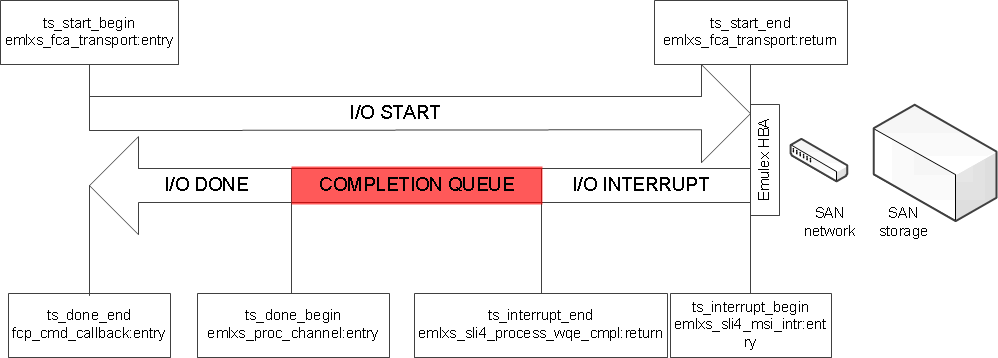
The question is, why some packages stay longer in the completion queue.
Let’s start with examining the activity in the I/O done thread:
#!/bin/sbin/dtrace
fbt:::entry
/ (uintptr_t)curthread->t_startpc == (uintptr_t)&emlxs`emlxs_thread && stackdepth <= 5 /
{
self->ts_started[caller,probefunc,stackdepth] = timestamp ;
}
fbt:::return
/ self->ts_started[caller,probefunc,stackdepth] /
{
@[caller,probefunc,stackdepth] = quantize((timestamp - self->ts_started[caller,probefunc,stackdepth])/1000000) ;
self->ts_started[caller,probefunc,stackdepth] = 0 ;
}
tick-1s
{
printf("\n\n%Y\n",walltimestamp);
printa("%a %s %d %@d\n",@);
trunc(@);
}
[...truncated...]
unix`swtch+0x165 resume 4
value ------------- Distribution ------------- count
-1 | 0
0 |@ 59
1 |@@ 116
2 |@@@@@ 270
4 |@@@@@@ 353
8 |@@@@@@@@@ 505
16 |@@@@@@@@ 447
32 |@@@@@@@ 419
64 |@@ 120
128 |@ 38
256 | 14
512 | 1
1024 | 0
[...truncated...]Warning: the dtrace script above causes performance overhead. Don’t run it on a production system.
It can be seen, that there are outliers when executing resume procedure lasting up to 2 seconds. resume code is called to handle the swithing of the thread on the processor. The outliers can also be confirmed by using a less invasive script:
#!/usr/sbin/dtrace
fbt::cv_wait:entry
/ caller >= (uintptr_t)&emlxs`emlxs_thread && caller < (uintptr_t)&emlxs`emlxs_thread+sizeof(emlxs`emlxs_thread) /
{
self->cv_wait = 1 ;
}
fbt::resume:entry
/ self->cv_wait /
{
self->ts_started[stackdepth] = timestamp ;
}
fbt::resume:return
/ self->ts_started[stackdepth] /
{
@["resume(ms)"] = quantize((timestamp - self->ts_started[stackdepth])/1000000);
self->ts_started[stackdepth] = 0 ;
}
tick-1s
{
printa(@);
trunc(@);
}
resume(ms)
value ------------- Distribution ------------- count
-1 | 0
0 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ 11145
1 |@@@@@@@@ 2856
2 |@@@ 1017
4 | 166
8 | 6
16 | 2
32 | 4
64 | 29
128 | 4
256 | 0
512 | 0
1024 | 1
2048 | 0Furthermore, the long resumes correlate with I/O outliers.
On one server I replaced the Emulex HBA with QLogic. After doing so, the problem with the occasional slow I/O by the oracle database log writer process was resolved!
By using DTrace and looking into the source code of the Emulex driver I explored differences in the internal functioning between the both device drivers.
Comparison with QLogic
Solaris Task Queues
First, I’ll take a look at the completion stack of the qlc driver:
dtrace -n 'fbt:scsi::entry { @[stack()] = count() }'
[...truncated...]
scsi_vhci`vhci_intr+0xb6
scsi`scsi_hba_pkt_comp+0x293
fcp`fcp_post_callback+0x19
fcp`fcp_cmd_callback+0x72
qlc`qlc_completion_thread+0xa4
genunix`taskq_thread+0x27e
unix`thread_start+0x8
[...truncated...]Having genunix`taskq_thread on the stack tells us that the QLogic driver, unlike the Emulex, uses the Solaris task queues for queueing incoming packets. This can be confirmed by running the kstat command:
kstat -c taskq
[...truncated...]
module: unix instance: 0
name: qlc_0_comp_thd class: taskq
crtime 1453.363526517
executed 0
maxtasks 8
nactive 8
nalloc 8
pid 0
priority 99
snaptime 1199076.69870013
tasks 8
threads 8
totaltime 0
[...truncated...]In the example above the maximum of 8 threads is configured, but the kernel adjusts the number of threads dynamically depending on the workload.
The interrupt thread puts the packet in the single task queue which is then asynchronously processed by the completion threads. Task queues are built and optimized for postponing some tasks and delegating their execution to another kernel thread. The facility is typically used by drivers. Usually, the tasks are dispatched from interrupt context.
On the contrary, the Emulex driver doesn’t rely on task queues. Instead, they create 8 completion queues per HBA which are implemented as circular linked lists. Each completion queue is protected by its own mutex: either an interrupt thread or a completion thread can access a queue. After the interrupt handler puts a packet on a queue it sends a signal to the corresponding completion thread by calling the function cv_signal and supplying the reference to the conditional variable. The completion thread, which is waiting in the cv_wait, wakes up, gets switched on the CPU, enters the mutex, and finally processes the packet. As a consequence, the time spent in resume contributes to the overall I/O latency.
For those willing to explore the implementation in more detail, I’m providing the references in the source code of the Emulex driver:
emlxs_thread_trigger2 function is called from interrupt context:
emlxs_thread_trigger2(emlxs_thread_t *ethread, void (*func) (), CHANNEL *cp)
{
/*
* If the thread lock can be acquired,
* it is in one of these states:
* 1. Thread not started.
* 2. Thread asleep.
* 3. Thread busy.
* 4. Thread ended.
*/
...
mutex_enter(ðread->lock);
...
...
if (ethread->flags & EMLXS_THREAD_ASLEEP) {
cv_signal(ðread->cv_flag);
}
mutex_exit(ðread->lock);
return;
} /* emlxs_thread_trigger2() */
emlxs_thread is the startigng function in the completion thread:
emlxs_thread(emlxs_thread_t *ethread)
{
...
mutex_enter(ðread->lock);
ethread->flags |= EMLXS_THREAD_STARTED;
while (!(ethread->flags & EMLXS_THREAD_KILLED)) {
if (!(ethread->flags & EMLXS_THREAD_TRIGGERED)) {
ethread->flags |= EMLXS_THREAD_ASLEEP;
cv_wait(ðread->cv_flag, ðread->lock);
}Thread Priorities
Besides using task queues there is another difference between both drivers which might have an impact on the process of context switching – thread priorities. From the kstat -c taskq output in the previous section it can be seen that the completion threads are running under the priority 99. In contrast, Emulex threads are running with the lower priority 97:
#!/usr/sbin/dtrace -s
# pragma D option quiet
fbt:::entry
/ caller >= (uintptr_t)&emlxs`emlxs_thread && caller < (uintptr_t)&emlxs`emlxs_thread+sizeof(emlxs`emlxs_thread) /
{
printf("prio: %d\n",curthread->t_pri);
exit(0);
}
prio: 97The Emulex thread has to compete with the ZFS and lot of other kernel threads which run with higher priority (99). Unfortunately, I couldn’t find a parameter for adjusting the default priority of the Emulex completion threads.
Next Steps
Replacing Emulex HBAs with Qlogic resolved the problem with the I/O outliers.
Nevertheless, we opened a service request. The Emulex development acknowledged the problem and offered us to rewrite the device driver in the following way: the completion thread will be removed and whole processing would be done in the interrupt thread. This should completely remove the latencies caused by the completion queue. However, I’m curious to see how this change will impact the kernel CPU consumption as the interrupts require spin mutex locks (the current implementation with the completion thread uses adaptive mutex locks).
Updates
18.07.2016
Oracle delivered the patch for the following bug which indeed helped to reduce the latency on the Emulex HBA driver on the busy server:
Release : Solaris 11.3 SRU # 8.7.0
Platform : i386
Bug(s) addressed :
23075272 : emlxs completion thread model can affect performance on busy systems
Package(s) included :
pkg:/driver/fc/emlxs
For me it is not clear, what exactly has changed, but I can see by observing stack traces that the completion thread was not removed.
Additional Information for ZFS Users
Setting user_reserve_hint_pct, which is the default parameter for limiting ZFS ARC has a negative impact on the latencies on the HBA driver. I elaborated on this here .
Conclusion
The Qlogic (QLC) HBA driver has lower latencies than Emulex driver. There are two implementation differences which might explain the difference in the behavior:
- the completion thread of the QLC driver is implemented by the means of the Solaris task queues which generally operates with less completion threads.
- the QLC completion threads are running with higher priority (99) than Emulex completion threads (97).
The Emulex development is willing to rewrite the driver to entirely eliminate the completion threads and handle the whole processing in the interrupt thread. I’m eager to test the changes and write about the results.
References
- Richard Dougall and Jim Mauro: Solaris Internals
- Brendan Gregg and Jim Mauro: DTrace Dynamic Tracing in Oracle Solaris
- Oracle Corporation: Writing Device Drivers