There is a substantial difference in how MS SQL Server and Oracle estimate the cost of a sort operation. The critical point isn’t in the algorithm itself. As we shall see, the problem exists rather on a much more basic level – in the inputs variables. On the one hand, Oracle relies on column statistics to produce accurate estimates. On the other hand, MS SQL Server uses data type size declared in the column definition. But this value is just the static maximum size that a column can store. The actual data size is, in fact, often much lower. Consequently, the estimates will be out of the ballpark in such cases. It goes without saying that this can have a detrimental effect on performance. I’ll be showing such a case and provide a workaround for affected queries.
But first of all, let me demonstrate how both products calculate the sort cost. The versions I used are SQL Server 2019 and Oracle 19c.
Oracle
I’ll be using the following data model with Oracle:
create table t (
c_type_size_1_length_1 varchar2(1),
c_type_size_4000_length_1 varchar2(4000),
c_type_size_4000_length_4000 varchar2(4000)
);
insert into t
select 'A', 'A', LPAD('A',4000,'A') from dual connect by level<=1e4 ;
commit ;
exec dbms_stats.gather_table_stats(null,'T');Basically, I created a table with three varchar2 columns. I inserted a single character into two columns with different max sizes: varchar2(1) and varchar2(4000). Finally, I inserted a long string into the varchar2(4000) column.
With the following statements we can observe how the calculation changes over two dimensions. One is the data type size in the column definition. The other is the actual data size:
select c_type_size_1_length_1 from t order by 1 ;
select c_type_size_4000_length_1 from t order by 1 ;
select c_type_size_4000_length_4000 from t order by 1 ;
Here’s, for example, the execution plan for the last statement:
SELECT * FROM table(DBMS_XPLAN.DISPLAY_CURSOR);
select c_type_size_4000_length_4000 from t order by 1
Plan hash value: 961378228
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 4037 (100)| |
| 1 | SORT ORDER BY | | 10000 | 38M| 39M| 4037 (1)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T | 10000 | 38M| | 737 (0)| 00:00:01 |
-----------------------------------------------------------------------------------
The cost attributed to the sort operation also entails the cost of its child operation. Consequently, the contribution of the sort operation itself is 3300 (4037–737).
The table below shows the sort costs for all three cases.
| actual size, max size | cost |
|---|---|
| 1, 1 | 1 |
| 1, 4000 | 1 |
| 4000, 4000 | 3300 |
As you can see, the cost didn’t increase after storing a single character in the varchar2(4000) column. The optimizer ignored the data type max size and used the actual data size. This is correct, because the resource consumption depends on the actual result set size and not on the defined column limit.
By the way, the following column statistics were used for estimating the actual data size:
col column_name format a30
select column_name,avg_col_len from dba_tab_columns where owner='SYS' and table_name='T';
COLUMN_NAME AVG_COL_LEN
------------------------------ -----------
C_TYPE_SIZE_1_LENGTH_1 2
C_TYPE_SIZE_4000_LENGTH_1 2
C_TYPE_SIZE_4000_LENGTH_4000 4001MS SQL Server
Unfortunately, MS SQL Server handles it the other way around. I’m using a similar data model to prove that:
create table t (
c_type_size_1_length_1 nvarchar(1),
c_type_size_4000_length_1 nvarchar(4000),
c_type_size_4000_length_4000 nvarchar(4000)
);
insert into t
SELECT TOP (10000)
'A', 'A', right(replicate('A',4000) + 'A',4000)
FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2
OPTION (MAXDOP 1);
CREATE STATISTICS c_type_size_1_length_1
ON t ( c_type_size_1_length_1 ) with fullscan ;
CREATE STATISTICS c_type_size_4000_length_1
ON t ( c_type_size_4000_length_1 ) with fullscan ;
CREATE STATISTICS c_type_size_4000_length_4000
ON t ( c_type_size_4000_length_4000 ) with fullscan ;
select c_type_size_1_length_1 from t order by 1 ;
select c_type_size_4000_length_1 from t order by 1 ;
select c_type_size_4000_length_4000 from t order by 1 ;In the following execution plan the result set contains a single character that was retrieved from the nvarchar(4000) column c_type_size_4000_length_1:
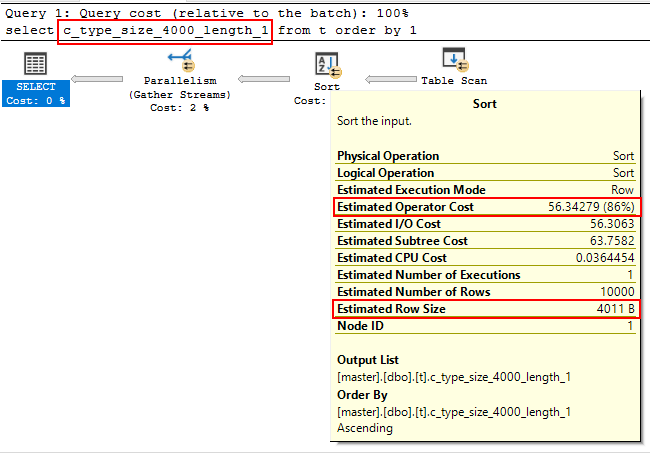
According to the output above, the data size used for the cost calculation is 4011B, even though the effective length of stored information was 1.
Curiously, the column statistics are accurate, but the optimizer didn’t use them at all:
Statistics for INDEX 'c_type_size_4000_length_1'.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Name Updated Rows Rows Sampled Steps Density Average Key Length String Index
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
c_type_size_4000_length_1 May 15 2020 11:04AM 10000 10000 1 0 2 YES 10000 0
All Density Average Length Columns
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 2 c_type_size_4000_length_1
Histogram Steps
RANGE_HI_KEY RANGE_ROWS EQ_ROWS DISTINCT_RANGE_ROWS AVG_RANGE_ROWS
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
A 0 10000 0 1Comparing the costs of sorting different columns also confirms that the data type size is used in the sort calculation cost:
| actual size, max size | cost |
|---|---|
| 1, 1 | 0.30734 |
| 1, 4000 | 56.34279 |
| 4000, 4000 | 56.34279 |
In other words, MS SQL Sever ignored the column statistics.
As we shall see later, a misestimate in the sort cost calculation can cause a butterfly effect leading to performance disasters with more complex execution plans.
Case study
Below is the model of a recent production issue:
drop table t_big
create table t_big( n1 integer, n2 integer )
insert into t_big
SELECT TOP (100000)
1, CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id]))
FROM sys.all_objects s1 CROSS JOIN sys.all_objects AS s2
OPTION (MAXDOP 1);
drop table t_small
create table t_small (
n1 integer,
c_type_size_1_length_1 nvarchar(1),
c_type_size_4000_length_1 nvarchar(4000)
)
insert into t_small values (1,'A','A')Let’s consider the following query that joins two tables producing a large result set due to the large driving table. For reference, we’re first selecting the small column, that is nvarchar(1), from the small table.
select
c_type_size_1_length_1
from t_big left outer join t_small on t_big.n1 = t_small.n1
order by t_big.n2
Expectedly, sort was applied to the hash join (HJ) output. The optimizer figured out correctly that this is an efficient plan, because the cost of sorting the result set containing 1 character column is low.
But the execution plan changes for worse after selecting the nvarchar(4000) column, although the data is exactly the same (only the declared data size changed):
select
c_type_size_4000_length_1
from t_big left outer join t_small on t_big.n1 = t_small.n1
order by t_big.n2 ;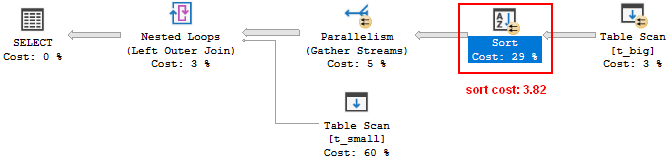
Simply put, because of the increased data type size (not the actual data, though!) the optimizer wrongly decided that sorting the whole result set at the end is too expensive. The large table was sorted before joining it with the small table by using nested loop (NL), instead. As a consequence, NL generated 100’000 page visits on the small table:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 't_big'. Scan count 3, logical reads 384, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 't_small'. Scan count 1, logical reads 100000, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.To quantify the magnitude of this damage, we’ll compare the execution statistics with those produced by the same query, but with HJ enforced:
select
c_type_size_4000_length_1
from t_big left outer hash join t_small on t_big.n1 = t_small.n1
order by t_big.n2The small table was accessed only once with HJ:
(100000 rows affected)
Table 't_big'. Scan count 3, logical reads 384, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 't_small'. Scan count 1, logical reads 1, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Workfile'. Scan count 2, logical reads 280, physical reads 31, page server reads 0, read-ahead reads 249, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
In conclusion, the sort cost overestimate caused an increase of logical reads by several orders of magnitude.
Anti-pattern
Based on the example above, we can generalize an anti-pattern to be found in the affected execution plans. Potentially troublesome queries can have a premature sort that feeds a NL, which, in turn, produces a logical read explosion.
Workaround
Is there a way to fix that (apart from obvious options of reducing the data type size to a bare minimum or eliminating unnecessary order by clauses)?
You can try producing a better execution plan and enforce it in the query store. To do this, you can temporarily increase the CPU cost weight to make the sort more attractive to the optimizer. The sort cost, namely, consists chiefly of the IO cost.
First, check the actual weights:
DBCC TRACEON (3604);
DBCC SHOWWEIGHTS;
DBCC Opt Weights CPU: 1.000000 IO: 1.000000 SPID 54Second, increase temporarily the CPU weight and clear the proccache:
DBCC SETCPUWEIGHT(100)
DBCC FREEPROCCACHE(Keep increasing the CPU weight until you get a better plan.)
Third, restore the old weight value once you got a good plan:
DBCC SETCPUWEIGHT(1)Finally, fix the new plan in the query store.
Below we can see such a plan that I enforced in the query store after applying the described procedure.
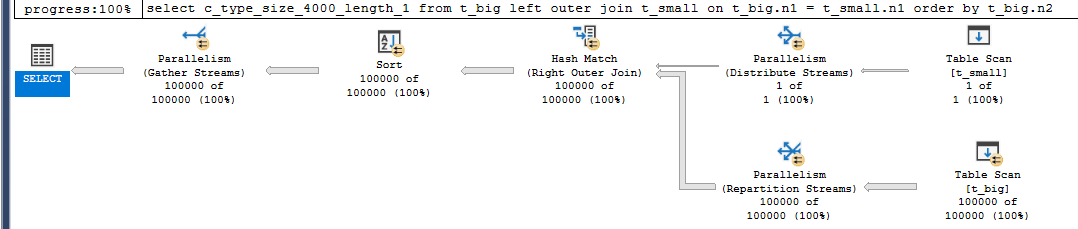
Summary
In summary, unlike Oracle, MS SQL Server uses the data type length from the column definition instead of column statistics for estimating sort operation cost. Consequently, the sort cost will be massively overestimated for underused columns. This will inevitably lead to bad plans. There isn’t a good solution for this. But in some cases, it is feasible to temporarily increase CPU weight to obtain a better plan that can then be pinned in the query store.
Related blog posts
In this blog post I didn’t cover any details of the sort calculation. I’ve been focusing on a very specific inefficiency in MS SQL Server, instead, and comparing it to Oracle.
But I was already dealing in detail with the sort cost calculation in Oracle in the following articles:
- IO Sort Calculation : researching Oracle C functions participating in the calculation, formulae, PL/SQL sort cost calculator
- IO Sort Calculation (2): expanding on math underpinning the calculation