ORM
In a nutshell, an object-relational mapper (ORM) is a framework that converts data in a database to application code objects and vice versa. Its main purpose is to simplify coding. There is also a micro ORM – a lightweight ORM, which performs better than a full featured ORM. Dapper is one such micro ORM for .NET. It can map a single row to an object. Further, it can map a row containing data from multiple tables to multiple object types in a single call. But, what it can’t do, is to populate nested objects, like the following one:
public class Customer
{
public int CustomerId;
public string Name;
public List<Order> Orders;
}
public class Order
{
public int Id;
public int Amount ;
public int CustomerId;
} Not only does the Customer class above contain customer data, but also a list of orders for a customer. So, the objects have to be initialized by iterating over rows obtained by the join of customers and orders tables. This is how this can be achieved with Dapper:
var customersDictionary = new Dictionary<int, customer="">();
rows = connection.Query<customer, customer="" order,="">(sql,
(c, o) =>
{
Customer customer;
if (!customersDictionary.TryGetValue(c.Id, out customer))
{
customersDictionary.Add(c.Id, customer = c);
}
if (customer.Orders == null)
{
customer.Orders = new List();
}
customer.Orders.Add(o);
return customer;
}, splitOn: "Id").Distinct().ToList();</customer,></int,>Slapper.Automapper comes in handy here – the code above can be replaced by a single line:
var customers = Slapper.AutoMapper.Map( connection.Query(sql) );Seductive, isn’t it?
But, wait… As we shall see, that’s not a free lunch. In fact, the price you pay in terms of performance may be huge.
Performance
The test consists of populating the list of Customer objects. For every row in the customers table there are 10 rows in the orders table. The tests are performed for different numbers of rows. I used SQL Server 2017, but the results can be extrapolated to any database products, as the test case is designed to stress the ORM, not the database.
Three types of tests were performed:
- PlainSQL test: it provides a reference. It iterates over the rows and populates an object for each selected row without using any ORMs.
- Dapper test: uses Dapper micro ORM for populating customer data in the object and a custom code to populate the Orders list for each customer.
- Slapper.Automapper test: uses Slapper.Automapper framework to populate the list of Customer objects.
The following graph displays the test results:
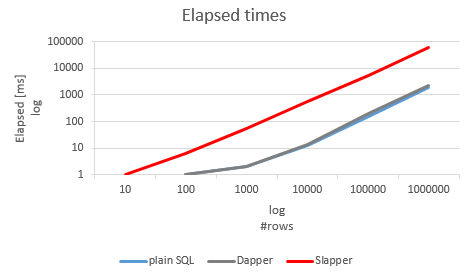
As you can see, Slapper.Autodapper introduces a massive overhead. In contrast, the overhead of Dapper is insignificant.
Note that due to the logarithmic scale on both axis, the overhead is much larger than it visually appears. As the overhead per row is constant, the optimized queries returning many rows will be most affected.
Profiling .NET
The reason for this serious performance degradation becomes obvious when looking at the profiled .NET execution when the query returned 100’000 rows:

As you can see, Slapper.Automapper relies on Dapper. However, only 5% was spent within the Dapper code. To get an idea what was executed we have to look deeper into the stack:
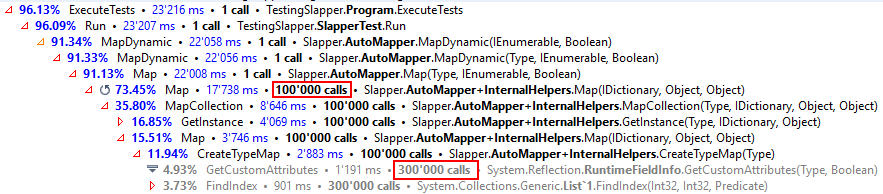
Some procedures were executed 100’000 times, that is, for every row. We can also see that the introspection (System.Reflection.RuntimeFieldInfo.GetCustomAttributes) was executed 300’000 times – which equals the number of rows multiplied by the number of non-id attributes. Introspection discovers and accesses metadata. Relying on the introspection came to no surprise, because Slapper.AutoMapper converts dynamic data into strongly typed data types. But, the problem is that the mapping code gets executed for each row, instead of just once at the beginning. Consequently, the efficiency could be dramatically improved by simply caching the mapping results.
Testing framework
I performed tests with a little home-grown framework written in C#. It’s very basic – I quickly developed it to quantify the overhead while troubleshooting a production issue.
There are a couple of parameters that can be configured:
| Parameter | Meaning |
|---|---|
| connectionStrings | database connection string |
| Iterations | number of tests to perform (for each type) |
| Rows | number of customers rows to select |
| Threads | number of parallel threads |
| Tests | comma-separated list of test types (PlainSQLTest,DapperTest,SlapperTest) |
| Verbosity | 0 - basic information with the median elapsed times 1- elapsed time for each run 2 - first three rows for each execution (I used 1 and 2 only during development) |
Use create_test_data.sql for creating test data.
To test with another database product you’d need to: replace the driver, adjust the connect string and adapt create_test_data.sql accordingly.
To test another ORM, add a test class which implements the ITest interface. If the ORM populates Customer object, it’s more convenient to inherit the abstract class TestReturnsObjectList , which itself implements ITest. Also, don’t forget to specify the class name in the configuration parameter Tests.
If the framework proves useful I’ll define an interface class for test cases, so that they can be easily added and customized without touching the core.
Conclusion
In conclusion, developers love using ORMs to simplify the application code. On the downside, it’s a black box and an additional abstraction layer, which might give rise to performance problems with non-obvious root causes. When complaining about “database problems”, developers are often mistaking ORM API calls for database calls. On the other hand, DBAs can’t see any issues in the database when the time is spent within the ORM. Consequently, the inability to quickly identify the root cause can elicit finger pointing and unproductive discussions. Understanding the fundamental principle that an ORM call comprises of more than just a database call, can significantly reduce the resolution time and improve the collaboration. Also, learning how to quickly triage by using database instrumentation and application code profiling pays high dividends. Finally, I provided a framework for building models for quantifying the ORM performance overhead.
Hello man,
We also have the performance issue with mapping complex objects by using Slapper.AutoMapper . We think the problem come from that the lib using reflection to map object. We have an idea to use source code generator Microsoft.CodeAnalysis.ISourceGenerator for mapping complex objects instead of using Slapper. But we don’t find any open sources for this topic, can you give me some opinion on this, thank you?
I don’t have a recommendation, but whatever you decide to use, test with your application. In this particular case, the application falled back on Dapper after learning about the Slapper overhead. Good luck!